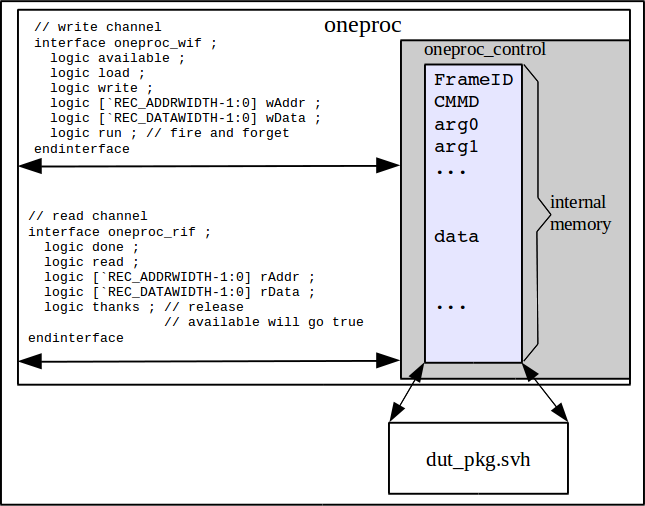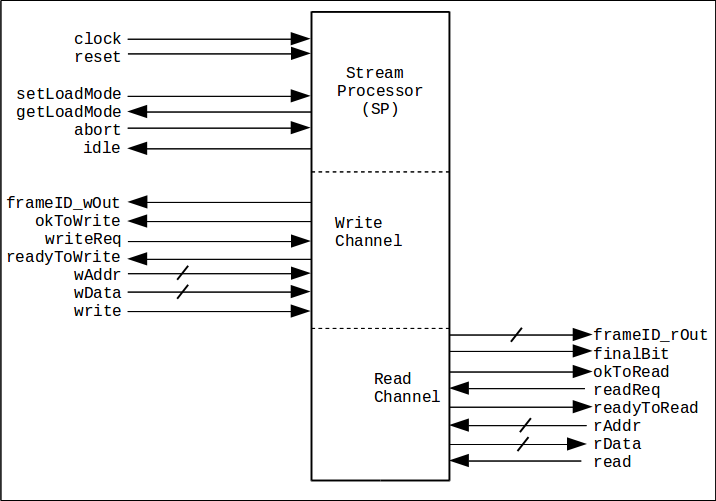
This section describes the generic stream processor, the interfaces, some internals, and how it is expected to be used. This section elaborates on the Overview but stops short of providing heavy details. What is described here is how to use the SP independent of any particular function it will perform. Here is a block diagram again for reference. The bus interface signals are fully described in the specification.
In brief:
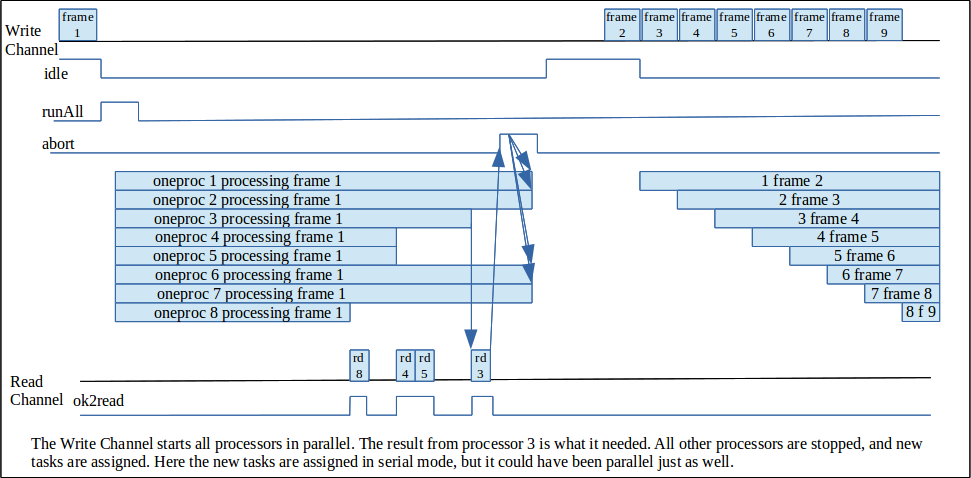
abort signal is provided on the write channel and asserting it will cause all computational units to abandon processing and return to idle.
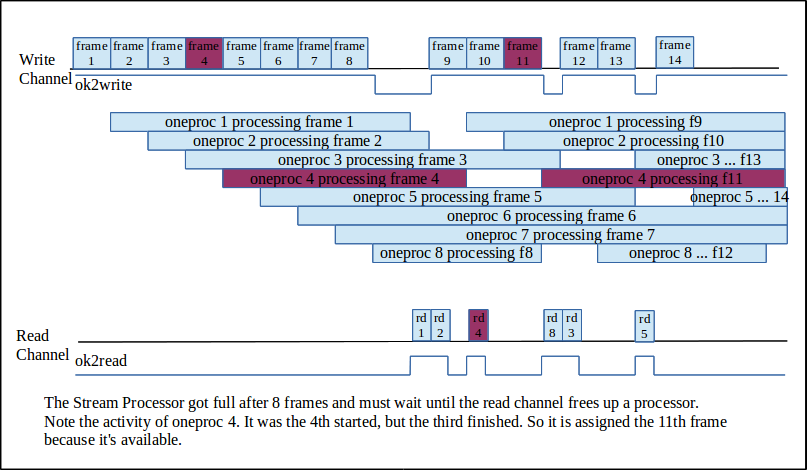
ok2write indicates that at least one processing unit is available.
ok2read indicates that at least one processing unit is done and results can be read.
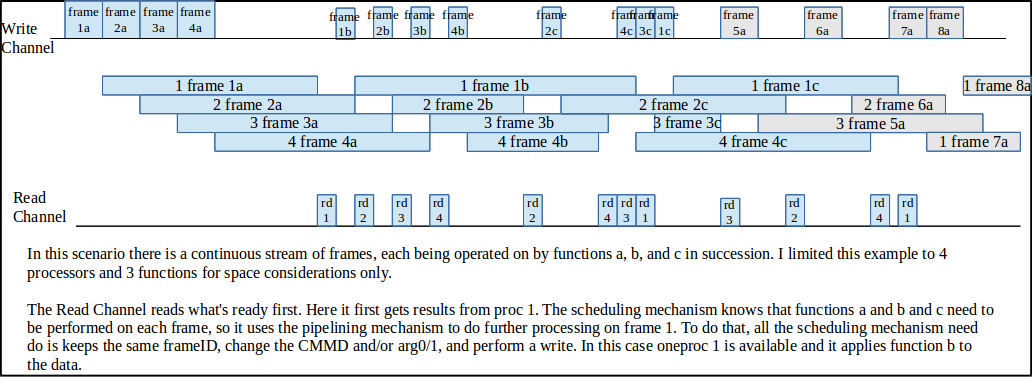
The core(s) of a stream processor are the "oneproc" units. They contain some number of kernel functions. In this project M = 2.
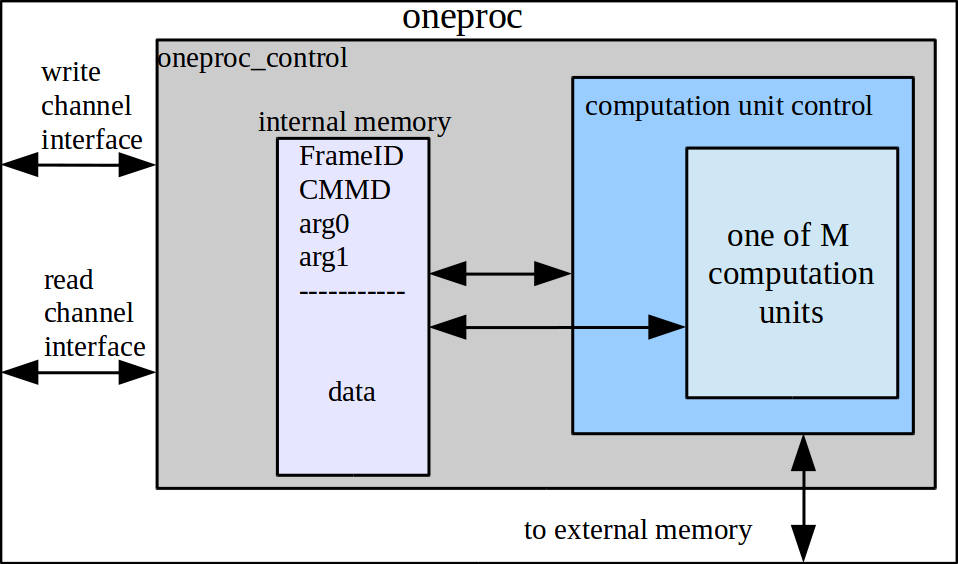
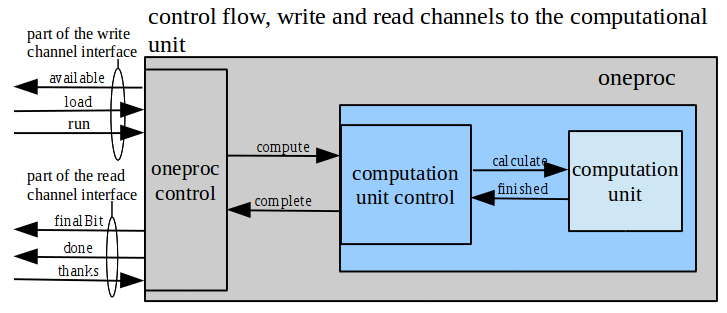
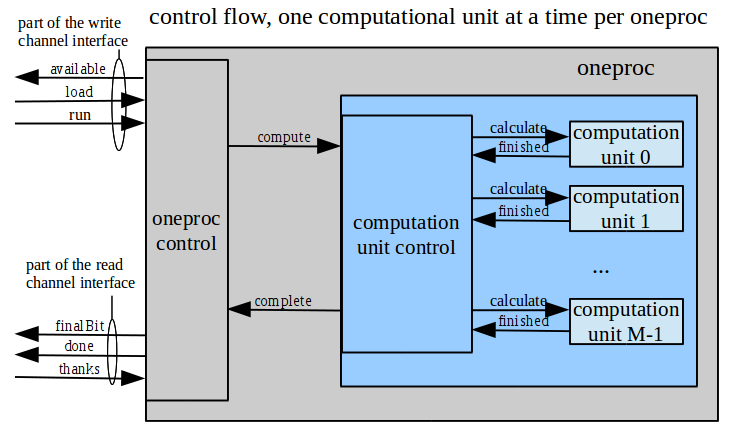
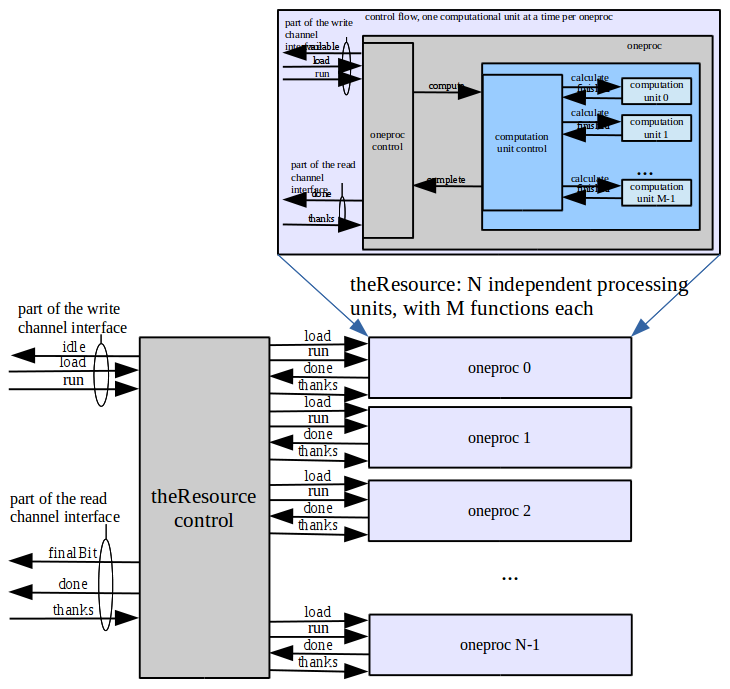
ok2write, and the read channel reads when it's ok2read. On reads, it is the responsibility of the user of the stream processor to know how to interpret the read data from the data record. The frameID is provided for such an accounting mechanism.