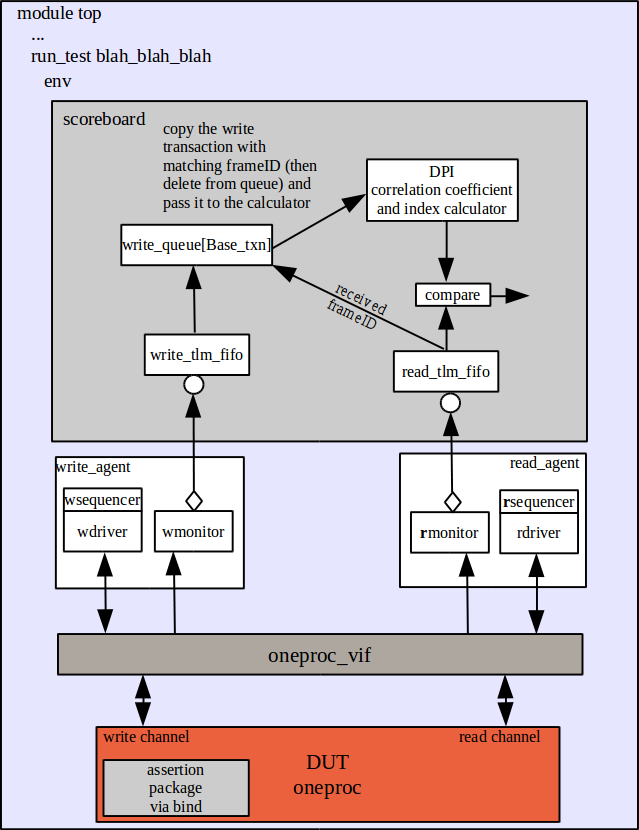
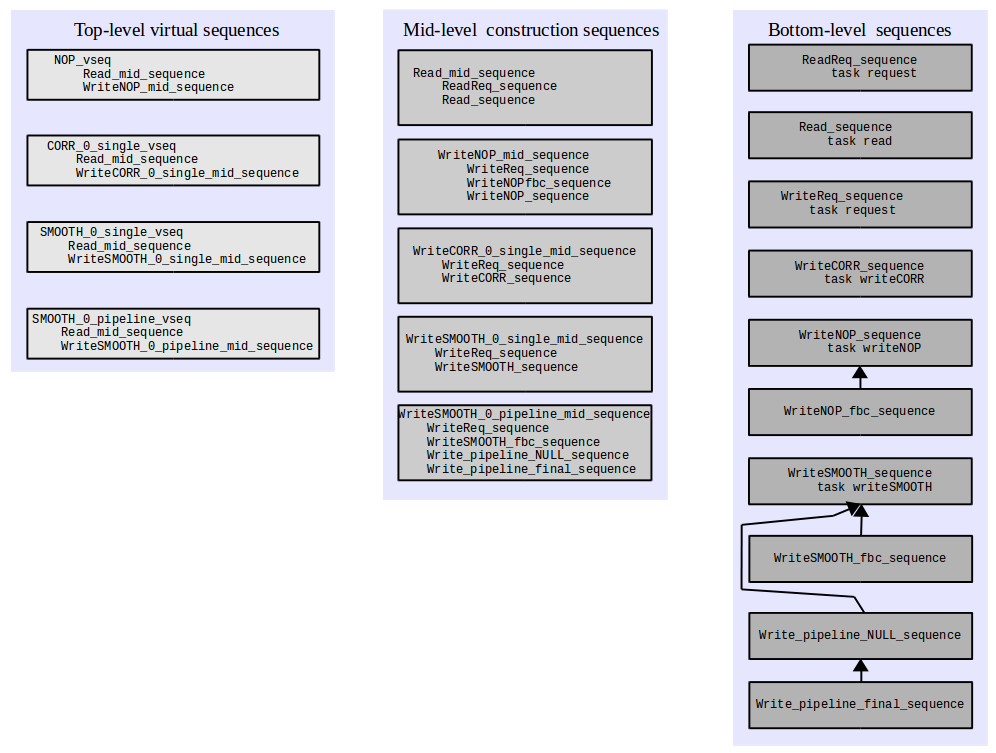
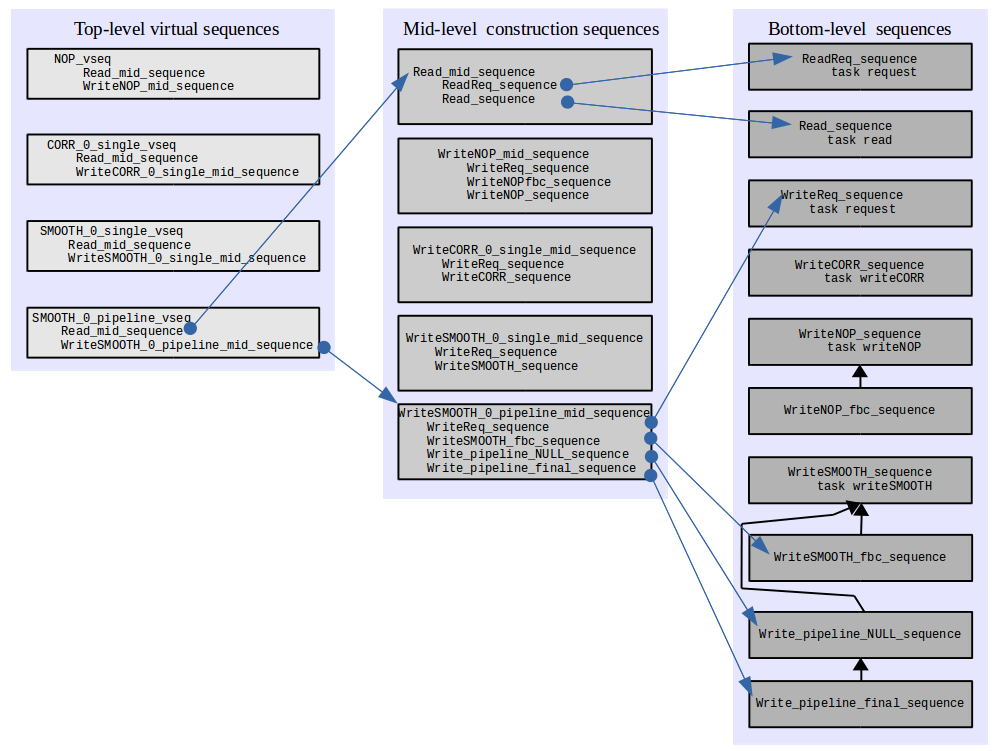
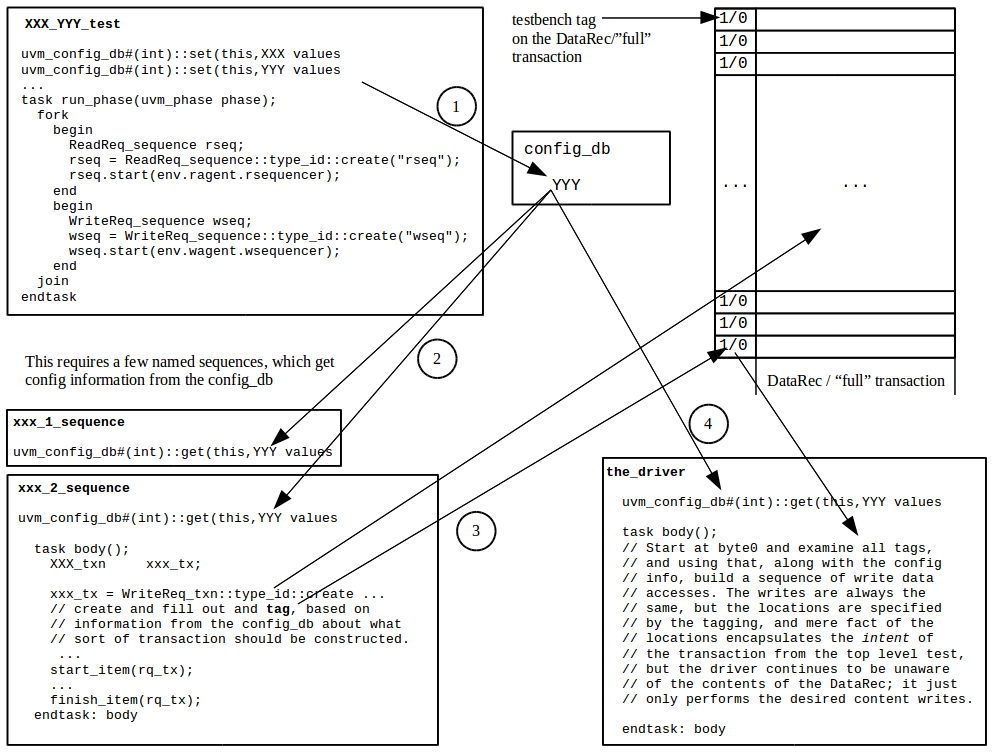
////////////////////////////////////////////////////////////////////
// What A Record Is
// A "record" is what is contained in the oneproc's memory.
// The content and meaning of a record depend on the process, meaning
// that they depend on the particulars of the Stream Processor's
// implemented computational unit.
//
// A record is abstracted here into the form of a matrix, R x C, or
// REC_ADDRWIDTH x REC_DATAWIDTH
// The geometry R x C is:
// R is the number of rows of data, (addresses)
// C is the number of columns (byte selects),
// so, bare, it's just a memory.
//
// Each column is one byte, so a 4x3 record would be 4 rows of 3 bytes:
// byte2, byte1, byte0 | addr m+0
// byte2, byte1, byte0 | addr m+1
// byte2, byte1, byte0 | addr m+2
// byte2, byte1, byte0 | addr m+3
//
// The beginning of a record is column 0, row 0.
// The natural word size is based on the number of columns. Above, the
// natural word size is 3 columns. 3 bytes. 24 bits.
//
// While the geometry of a oneproc unit's memory is flexible, all
// computational units in a oneproc unit must adhere to one-in-the-same
// geometry as specified by REC_DATAWIDTH and REC_ADDRWIDTH.
//
// The only incontrovertible fields are the first four bytes, and they are:
// byte00 - frameID, 256 possible values which are NOT interpreted at all
// by the stream processor. They are for an external task manager.
// byte01 - CMMD. There are 127 possible commands. Bit 7 is dedicated as a
// "final" bit. This is part of the mechanism for pipelining. When
// bit 7==0 it serves as an indication to the read channel that
// the processing is not totally done, and that following the
// read of the first 4 bytes of the DataRec the read channel
// should say thanks and release the oneproc.
// byte02 - arg0. See the specific command for details.
// byte03 - arg1. See the specific command for details.
////////////////////////////////////////////////////////////////////
`ifndef DUT_PKG
`define DUT_PKG
package dut_pkg ;
//----------------------------------------------------------------------------
// This is the *specific* record format for the "Hello World" StreamProc,
// HWSP, pearsons_r computational unit. CMMD == CORR.
// It is a 64 byte record of 16 32-bit words organized as follows:
// 31:24 23:16 15:8 7:0
// byte3 byte2 byte1 byte0
// 0 arg1 arg0 CMMD frameID when arg0==1 it means end when cc >= arg1
// 1 SL SS RL RS // S[]Length("32"), S[0]Start("24"), Ref[]Length("11"), Ref[0]Start("12")
// 2 res status offset cc
// 3 l l e H
// 4 o w o
// 5 NA d l r
// 6 S[3] S[2] S[1] S[0]
// 7 S[7] S[6] S[5] S[4]
// 8 S[11] S[10] S[9] S[8]
// 9 S[15] S[14] S[13] S[12]
// 10 S[19] S[18] S[17] S[16]
// 11 S[23] S[22] S[21] S[20]
// 12 S[27] S[26] S[25] S[24]
// 13 S[31] S[30] S[29] S[28]
// 14 unused unused unused unused
// 15 unused unused unused unused
//
// CORR : with arg0 == 0, arg1 is ignored
// CORR : with arg0 == 0, arg1 is ignored
// CORR : with arg0 == 1 the end-at-threshold is enabled, and arg1 is
// the threshold value for pearson's r.
// Normally device will try all 21 possible correlations by
// using the 21 different possible offsets, but with end-of-threshold
// enabled it will stop the firts time the cc comes back >= arg1.
`define HWLENGTH 11
// The define "SLENGTH 32" is NOT part of the DUT. It's the TB's decision. See the TBdefines
//----------------------------------------------------------------------------
// This is the *specific* record format for the "Hello World" StreamProc,
// HWSP, smoothing computational unit. CMMD == SMOOTH.
// It is a 64 byte record of 16 32-bit words organized as follows:
// 31:24 23:16 15:8 7:0
// byte3 byte2 byte1 byte0
// 0 arg1 arg0 CMMD frameID //
// 1 res status DL DS // D[]Length, D[0]Start
// 2 S[3] S[2] S[1] S[0]
// 3 S[7] S[6] S[5] S[4]
// 4 S[11] S[10] S[9] S[8]
// ...
// X S[N] S[N-1] S[N-2] S[N-3] (for example)
// 15 ...
//
//
// For the array S, S[0] to S[N-1], where
// S[0] = (byte4), and
// S[N-1] = (byte4) + (byte5),
// SMOOTH overwrites values by averaging:
//
// S0 = S[0] ;
// for (i=0; i < N-1; i++)
// S[i] = (S[i] + S[i+1])/2;
// S[N-1] = (select) ? S[N-1] : (S[N-1] + S[0])/2 ;
//
// The value in byte5 indicates N, the length of the array.
// The value of byte4 indicates the offset from 0 where the array begins.
// Note that the array cannot begin at an offset less than 8 without
// overwriting the header information and reserved bytes.
// This puts a lower limit of 'hC for DS/byte4.
// Note also that with a 64 byte memory, the absolute maximum number for
// length, for the value of N, is 63-12 = 51.
// If arg0[0] == 0, leave the value of S[N-1] untouched.
// If arg0[0] == 1, S[N-1] is averaged with the original value of S[0].
// A value of DL > 63-12 yields unconsidered writing behaviour.
//----------------------------------------------------------------------------
// This is the *specific* record format for the "Hello World" StreamProc,
// HWSP, test computational unit, CMMD == KS.
// It is a 64 byte record of 16 32-bit words organized as follows:
// 31:24 23:16 15:8 7:0
// byte3 byte2 byte1 byte0
// 0 arg1 arg0 CMMD frameID arg0 and arg1 not yet specified
// 1 duration duration SA0 Source Address
// 1 SA3 SA2 SA1 SA0 Source Address
// 2 DA3 DA2 DA1 DA0 Destination Address
// 3 len3 len2 len1 len0 Lenght
// 4 unused unused unused unused
// ...
// 15 unused unused unused unused
//
// KS, the Karplus-Strong plucked-string algorithm is not yet implemented.
//----------------------------------------------------------------------------
// This is the *specific* record format for the "Hello World" StreamProc,
// HWSP, test computational unit, CMMD == WINDOW.
// It is a 64 byte record of 16 32-bit words organized as follows:
// 31:24 23:16 15:8 7:0
// byte3 byte2 byte1 byte0
// 0 arg1 arg0 CMMD frameID arg0 and arg1 not yet specified
// 1 SA3 SA2 SA1 SA0 Source Address
// 2 DA3 DA2 DA1 DA0 Destination Address
// 3 len3 len2 len1 len0 Lenght
// 4 unused unused unused unused
// ...
// 15 unused unused unused unused
//
// The windowing functions for DFT are not yet implemented
//----------------------------------------------------------------------------
// This is the *specific* record format for the "Hello World" StreamProc,
// HWSP, test computational unit, CMMD == TEST.
// It is a 64 byte record of 16 32-bit words organized as follows:
// 31:24 23:16 15:8 7:0
// byte3 byte2 byte1 byte0
// 0 arg1 arg0 CMMD frameID arg0 and arg1 not yet specified
// 1 rslt3 rslt2 rslt1 rslt0 for initial DMA tests, details coming later
// 2 < address pointer 1 > for initial DMA tests, details coming later
// 3 < address pointer 2 > for initial DMA tests, details coming later
// 4 unused unused unused unused
// ...
// 15 unused unused unused unused
//
// TEST is not yet implemented
`define RECORDSIZE 64
// The defines below specify a 32-bit write data width and 4-bit write address
// configuration.
// One will note that with REC_ADDRWIDTH and RECORDSIZE that REC_ROWS could be
// determined where needed. HOWEVER, rather than spread that little calculation
// around to every block that needs the non-given values, I'll just put them both
// here.
`define REC_DATAWIDTH 32
`define REC_ADDRWIDTH 4
`define REC_ROWS 16
// This is a placeholder for loading all oneprocs in parallel or serial.
// It is not connected to any functioning yet.
`define LOADMODE 1
// This is for the verification environment. The number of computational units
// should be of no concern to the RTL integrator of the stream processor *as a
// unit*.
`define HWSP_PROCS 8
typedef bit[`REC_DATAWIDTH-1:0] DataRec [`REC_ROWS] ;
typedef enum bit[6:0] { NOP, CORR, SMOOTH, KS, WINDOW, LFSR16X, TEST, BADCMMD } cmmd_type ;
// Keep pushing BADCMMD to the right.
endpackage
`endif
|