Basic UVM testbench for a Stream Processor
This is a from-scratch UVM testbench for testing stream processor type components. I have several projects more suited to custom stream processing and/or parallel processing than general purpose CPU computing, and this testbench is the basis for verifying those hardware components.
This testbench comes with a simple "Hello world detector" DUT. The DUT calculates the correlation coefficient of substrings v.s. the reference string "Hello world". The testbench uses virtual hierarchical sequences, constrained randomized transactions, a scoreboard that compares out-of-order process completion, and a reference model in C integrated via the DPI.
The most recent testbenches are on EDAplayground here:
 for the single processor unit testbench.
for the single processor unit testbench.
Acknowledgments
Thank you to the folks running and supporting EDA Playground. I couldn't have simulated without you.
A thank you to the folks running and supporting WaveDrom for a truly awesome tool. All the timing diagrams in the specification were drawn with WaveDrom. The json files for all the waveforms are here: wavedrom directory
Overview
I have a need for some computational resources, so of course I'll want to test those designs before I commit them to even an FPGA build. The UVM testbenches here provide that testing capability. Loosely described, at the top level these resources look like a peripheral or coprocessor that takes what you feed it and provides results some time later. The simplest picture might be this one:
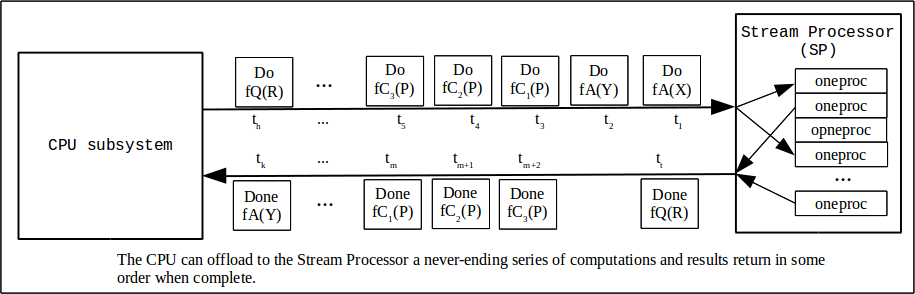
Those aren't D-sub-zeros in the diagram. It's "do this" and "do that" and "do the other thing". One writes records containing the kernel function command and the data to operate on ("do function X on data set Y") into one end of the resource via a write channel, and results are available at the other end via a read channel when the computation is complete. This class of computational units is known as Stream Processors (SPs).
There is no need (yet) to support any standard interface so I settled on a generic and pleasantly simple interface for the Stream Processor resource. On the outside it looks like a dual-port memory, albeit with "ready" outputs. On the inside it potentially changes the data written.
Here is a diagram of the interface. The interface is fully described in the specification.
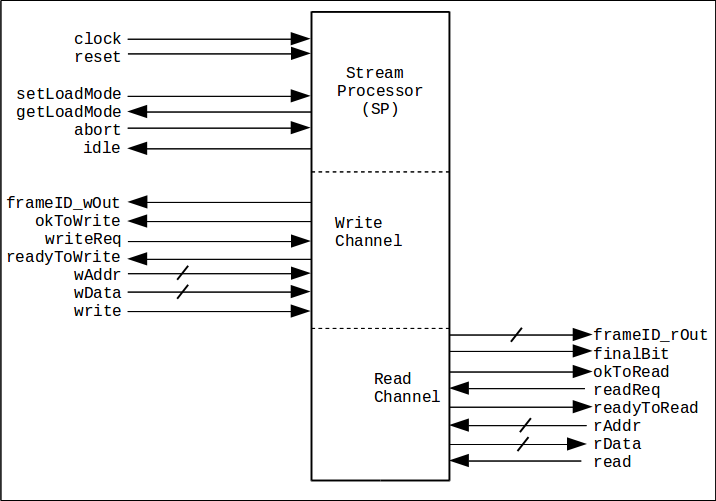
What is hidden behind the SP interface is an array of processing units, oneprocs, that implement the kernel functions. Oneproc units are assigned on a whoever's available next basis. The testbench described in this project is designed to be rapidly adapted to whatever functions I put in the resource and whatever use model I adopt per project. If I need a different function, I add it to the oneproc's capability. If I need more computational power, I add more oneprocs. From the outside it looks exactly the same.
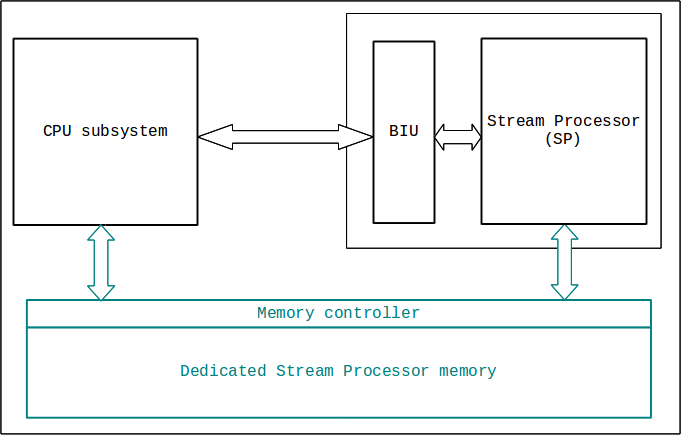
Here is a block diagram of how the resource will sit in the final system. The BIU converts the SP's interface to the native bus interface of the system it is placed into. The particular SP used in this project only operates on data written to its internal memory so it does not require an external memory as shown in blue. Larger data sets will naturally reside in memory and the oneproc units will address that external data independently.
This project documentation is divided into the following sections:
This overview,
The generic Device Under Test,
outlining the write and read channel interfaces of a generic SP with no stated function, and of a generic oneproc sub-module, again with no stated function,
The generic testbenches,
outlining the framework for a non-commital UVM testbench for the generic SP and oneproc DUTs described in The generic Device Under Test,
A specific Device Under Test,
describing the specific "Hello world detector" function and the smoothing function,
Doing the math2for Pearson's r,
discussing some hardware limits,
DUT HWSP specification and integrated testplan,
the complete specification and testplan,
Testbench qualification,
how the testbench itself will be tested, and
The specific testbenches,
for testing the "Hello world detector" SP and the oneproc unit.
Click "next section →" in the navigation bar above to read in order, or jump directly to any section from the "Index".
However
There are different ways to document. The outline above proceeds from the general to the more specific, ending with a testplan and code.
But what if you just thought, "Hey. You mean there is a ready-made testbench where I can drop in a computational unit of my own design and start testing it right away? What do I need to do?" then this page here integrating a new computational unit is where to go.
TODO:
Now that the basic tests are done and computations verified,
[ ] Write the assertions.
[ ] Bind in the assertions that need to be embedded in the RTL.
[ ] Rerun all functional tests on oneproc
[ ] Add the random tests on oneproc
[ ] Add the oneproc code coverage
[ ] Post-implementation review and finish making as many components of the testbench as possible maximally reusable.
[ ] Run all functional tests on HWSP
[ ] Run random tests on HWSP
[ ] Swap out the behavioral math in oneproc for synthesizable RTL and verify it.
[ ] Get it into the Zynq
[ ] As discussed above, there are 4 classes of Stream Processors that this verification environment will handle. Those are:
- Serial Load Data Parallel SLDP (this is the current state of the RTL)
- Serial Load Task Parallel SLTP
- Parallel Load Data Parallel PLDP
- Parallel Load Task Parallel PLTP
So far I've only used the SLDP. Later on I'll add the SLTP, PLDP, and PLTP capabilities to the HWSP. Then I'll have something to configure, and I'll add the necessary configuration class.
Known issues:
[a] The testbench will hang if the number of reads does not match the number of writes because the processes will not complete, pending access to the DUT. Fix this on the read agent end ... it has no right to expect any number of completions, so it shouldn't be hanging.
[b] The testbench is terribly dependent on the detection of "Hello world", although the Stream Processor is not (that is, "Hello world" is hardcoded in the write sequence). So turn that write sequence into generic container and derive a HelloWorld sequence from it.
[DONE] I need to decouple the sequence and driver. Currently the sequence builds a transaction with knowledge of the data bus width at the DUT. That won't do. See the discussion above about the geometry of the DataRec above here. A single file should tell the testbench what sort of DataRecord it has and what the Write and Read channel bus widths are. This is kind of a unusual because normally one would not let the DUT have so much power. It's as though the DUT decides which sequences and protocol to use.
This is a work in progress